Archive
Optimization 본문
728x90
Udemy The Complete Neural Network Bootcamp 참고
Optimization
- batch gradient descent
- take all the samples in one iteration = 전체 사용해 update
- number of iterations per epoch = 1
- stochastic gradient descent
- take one sample at each iteration = 한 sample로 각각 update
- number of iterations per epoch = number of samples
- mini-batch gradient descent
- take the best of both batch and stochastic gradient descent
- number of iterations per epoch = number of samples / batch size
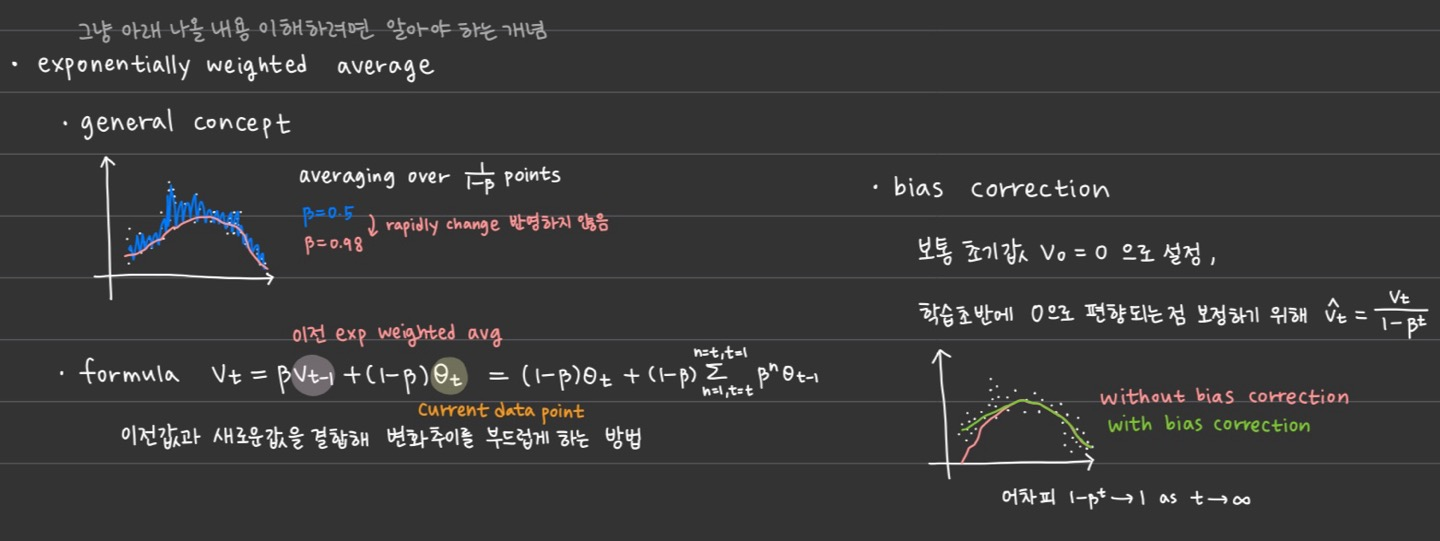
Optimization 변형
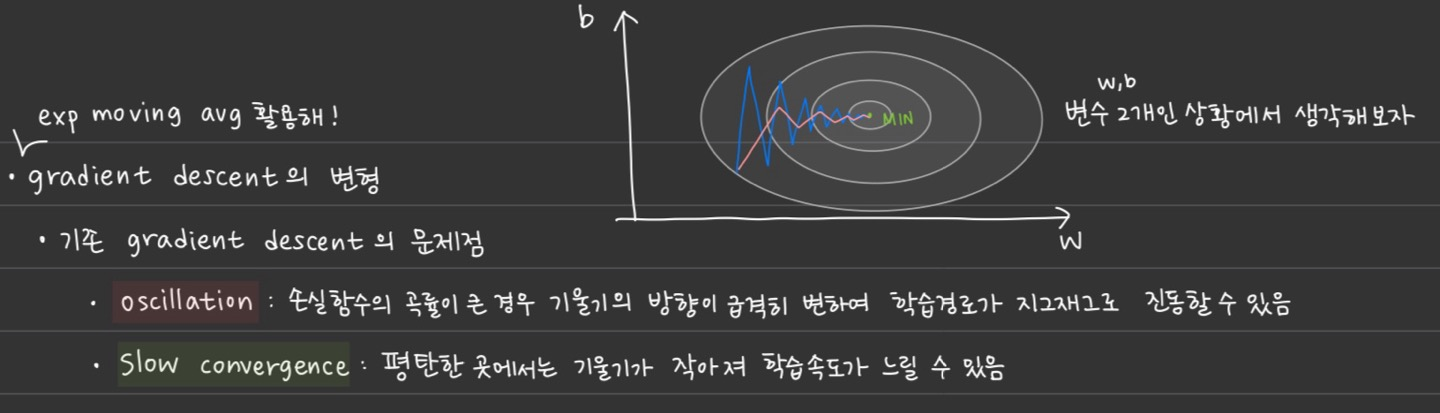
Stochastic Gradient Descent with momentum

RMS prop: adaptive learning rate method

Adaptive Moment Estimation Adam

Weight Decay

AMS Grad

728x90
'AI > Deep Learning' 카테고리의 다른 글
| Initialization (0) | 2024.12.07 |
|---|---|
| Hyperparameter Tuning (1) | 2024.12.07 |
| Over-fitting (1) | 2024.12.07 |
| Activation Function (2) | 2024.12.07 |
| Loss Function (2) | 2024.12.07 |
'AI/Deep Learning' Related Articles
more



