Archive
MySQL overview 본문
728x90
이것이 MySQL이다 8.0 (우재남, 한빛미디어) 참고
데이터리안 SQL CHEAT SHEET 참고
CRUD

DML data manipulation language 데이터 조작 언어
- 데이터 조작에 활용.
SELECT *
FROM table_ref
WHERE condition
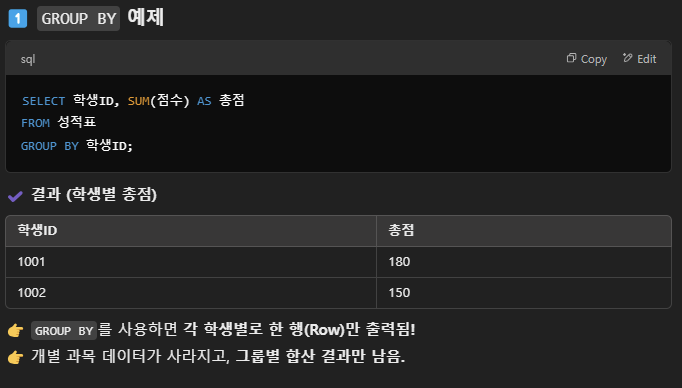
GROUP BY col_name
HAVING condition
ORDER BY col_name
LIMIT row_num;INSERT [INTO] table_ref VALUES (val1, val2, ...);UPDATE table_ref
SET col1=val1, col2=val2, ...
WHERE condition;DELETE FROM table_ref
WHERE condition
LIMIT num;DDL data definition language 데이터 정의 언어
- 데이터베이스, 테이블, 뷰, 인덱스 등 데이터베이스 개체를 생성.
- 삭제 및 변경할 때 roll-back 불가능하다는 특징이 있음.
1. 컬럼부터 정의해서 만들기
CREATE TABLE orders (
order_id STRING,
order_date DATE,
customer_id STRING
...
)
2. 기존 테이블을 활용해 새로운 테이블 만들기
CREATE TABLE orders_jan (
SELECT *
FROM orders
WHERE order_date BETWEEN '2020-01-01' AND '2020-01-31'
)
- 테이블 수정하기
ALTER TABLE orders ADD COLUMN cancel_date DATE; # 컬럼 추가
ALTER TABLE orders RENAME COLUMN cancel_date TO canceled_at; # 컬럼 이름 변경
ALTER TABLE orders DROP COLUMN canceled_at; # 컬럼 삭제
ALTER TABLE orders RENAME TO cancel_rename; # 테이블 이름 변경
- 테이블 삭제하기
DROP TABLE orders;DCL data control language
- 사용자에게 어떤 권한을 부여하거나 빼앗을 때 사용.
JOIN
Inner Join
SELECT *
FROM tbl_1 INNER JOIN tbl2 ON join_conditionOuter Join
SELECT *
FROM tbl1
LEFT | RIGHT | OUTER JOIN tbl2 ON conditionCase
CASE WHEN bool_exp THEN ...
END CASE;While
WHILE bool_exp DO
...
END WHILE;
-- ex.
myWhile: WHILE (i <= 100) DO
IF (i%7 = 0) THEN
SET i = i+1;
ITERATE myWhile;
END IF
SET hap = hap+i;
IF (hap > 1000) THEN LEAVE myWhile;
END IF;
SET i = i+1;
END WHILE;
SELECT hap;Declare
DECALRE action HANDLER FOR condition query;
-- ex.
DECLARE CONTINUE HANDLER FOR 1146 SELECT '테이블이 없어요' AS '메세지';WHERE절 서브 쿼리
단일행 서브 쿼리
- 서브 쿼리의 결과 값은 반드시 1개!
- 비교연산자와 함께 사용
SELECT *
FROM tips
WHERE bill > (SELECT AVG(bill) FROM tips)다중행 서브 쿼리
- 서브 쿼리의 결과 값은 행 1개 이상, 열 1개
- IN, NOT IN과 함께 사용
SELECT *
FROM tips
WHERE day IN (
SELECT day FROM tips
GROUP BY day
HAVING SUM(bill) >= 1500
)다중 컬럼 서브 쿼리
- 서브 쿼리의 결과 값은 행 1개 이상, 열 1개 이상
- IN, NOT IN과 함께 사용
SELECT *
FROM tips
WHERE (day, bill) IN (
SELECT day, MAX(bill)
FROM tips
GROUP BY day
)FROM절 서브 쿼리
- Alias 필수!
SELECT AVG(daily.sales)
FROM (
SELECT day, SUM(bills) AS sales FROM tips
GROUP BY day
) dailyWITH
# 1개일 때
WITH 별칭 AS (
쿼리
)
# 2개 이상일 때
WITH 별칭1 AS (
쿼리
), 별칭2 AS (
쿼리
)
Stored Program
Stored Procedure
DROP PROCEDURE IF EXISTS procedure_name;
DELIMITER $$
CREATE PROCEDURE procedure_name(
[IN]
[OUT]
)
BEGIN
...
END $$
DELIMITER;
CALL procedure_name();Stored Function
DELIMITER $$
CREATE FUNCTION function_name(parameter)
RETURNS data_type
BEGIN
...
RETURN return_value;
END $$
DELIMITER;
SELECT function_name();Trigger
CREATE
TRIGGER trigger_name trigger_time trigger_event
ON table_ref FOR EACH ROW
[trigger_order]
--
trigger_time: {BEFORE | AFTER}
trigger_event: {INSERT | UPDATE | DELETE}
trigger_order: {FOLLOWS | PRECEDES} other_trigger_nameAggregation Function 집계 함수
- 여러 개의 숫자를 하나의 숫자로 요약하는 것
대표값 계산하기
- 중앙값 계산하기
- PERCENTILE_CONT(): 백분율에 정확히 일치하는 값이 없을 경우, linear interpolation하여 값을 계산
(i.e. 실제 데이터에는 없는 값을 출력할 수도 있음) - PERCENTILE_DISC(): 백분율에 정확히 일치하는 값이 없을 경우, 가까이에 있는 선순위 데이터를 출력
(i.e. 실제 데이터에 있는 값만 출력함)
- PERCENTILE_CONT(): 백분율에 정확히 일치하는 값이 없을 경우, linear interpolation하여 값을 계산
SELECT PERCENTILE_CONT(0.5)
WITHIN GROUP (ORDER BY pm10)
AS median
FROM measurements
- 최빈값 계산하기
SELECT MODE()
WITHIN GROUP (ORDER BY pm10)
AS mode
FROM measurements;윈도우 함수
- 데이터 각 행을 유지하는 상태에서 집계 Aggregation 연산을 수행하는 함수
- GROUP BY를 활용해 집계하면, 데이터 자체를 그룹화하게 되면서, 개별 행이 사라짐

형태
함수() OVER ()
함수() OVER (PARTITION BY 컬럼)
함수() OVER (ORDER BY 컬럼)
함수() OVER (PARTITION BY 컬럼 ORDER BY 컬럼)자주 사용하는 함수!
- COUNT()
- SUM()
- AVG()
- MIN(), MAX()
- RANK(), DENSE_RANK()
- ROW_NUMBER()
- LEAD()
- LAG()
분포 함수
- CUME_DIST(): 누적 분포를 계산
- PERCENT_RANK(): 백분위를 계산
- NTILE(): 데이터를 N등분으로 나눔
그룹 내 행 순서 함수
- FIRST_VALUE(): 첫 번째 값을 선택
- LAST_VALUE(): 마지막 값을 선택
- NTH_VALUE(): N번째 값을 선택
Named Window
- 같은 윈도우를 반복해서 써야할 때, 별칭을 붙일 수 있는 편리 기능
SELECT
val,
ROW_NUMBER() OVER w AS 'rn',
RANK() OVER w AS 'r',
DENSE_RANK() OVER w AS 'dr',
FROM numbers
WINDOW w AS (ORDER BY val)
Frame

- 누적합
SELECT measured_at, pm10, SUM(pm10) OVER (ORDER BY measured_at ROWS UNBOUNDED PRECEDING) AS '누적합'
ORDER BY measured_at- 이동평균
SELECT measured_at, pm10, AVG(pm10) OVER (ORDER BY measured_at ROWS BETWEEN 1 PRECEDEING AND 1 FOLLOWING) AS '이동평균'
FROM measurements
ORDER BY measured_atData Modeling
- 데이터 모델링은 현실 세계의 데이터를 체계적으로 구조화하여 데이터베이스로 설계하는 것! 필수 속성은:
- 개체 Entity
- 속성 Attribute
- 관계 Relationship
정규화 원칙
- normalization 정규화: 데이터베이스에서 데이터 구조를 최적화!
- 데이터 중복 방지
- 데이터 일관성 유지: 한 곳에서 변경하면 모든 관련 데이터가 자동으로 바뀌도록
- 데이터 삽입 및 삭제 시 오류 방지
- 작은 테이블로 나눠서 검색 성능을 향상시키기도
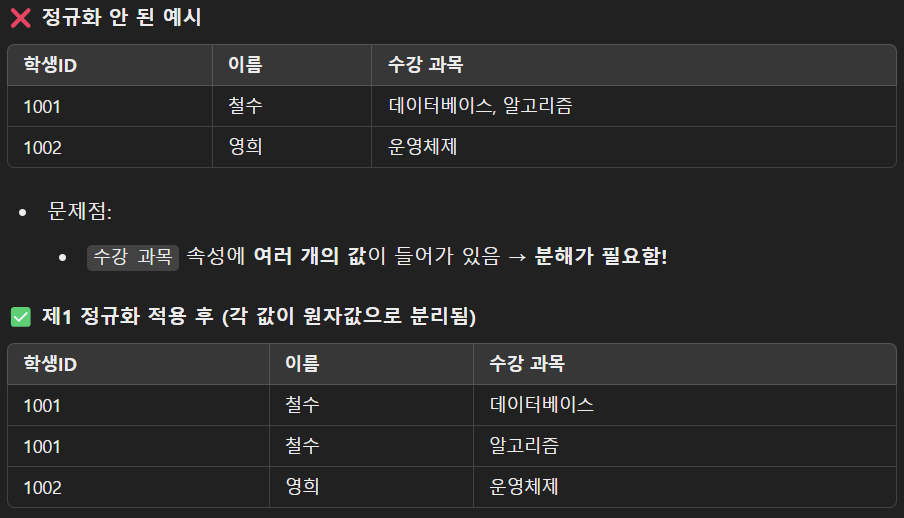
- 제1 정규화
- 모든 속성 값이 더 이상 분해할 수 없는 값을 가져야 함
(i.e. 각 칸에는 하나의 값만 들어가야 함) - 더보기
- 모든 속성 값이 더 이상 분해할 수 없는 값을 가져야 함
- 제2 정규화
- 제1 정규화를 만족하고, 후보키가 아닌 속성은 후보키 전체에 종속되어야 함
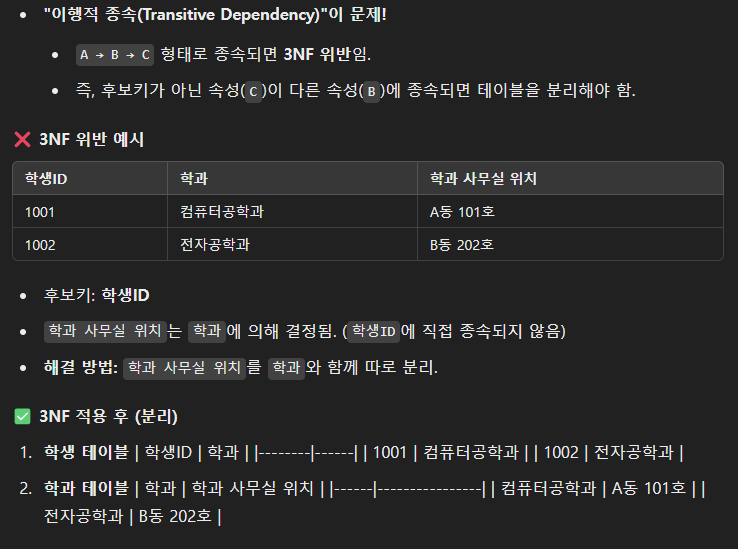
- 제3 정규화
- 제2 정규화를 만족하고, 후보키 이외의 모든 속성들은 서로 독립적이어야 함

Key의 종류
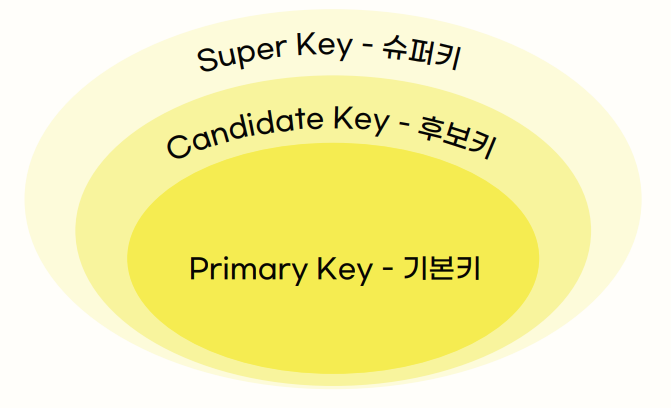
- 슈퍼 키: 데이터를 유일하게 식별할 수 있는 속성 집합
- 후보 키: 데이터를 유일하게 식별할 수 있는 최소한의 속성 집합
- 기본 키: 여러 후보 키 중 대표로 선택된 키
- 대체 키: 기본 키로 선택되지 않은 나머지 키
SQL 성능 최적화
- 데이터 필터링
- SELECT, WHERE, LIMIT 등 다양한 방법으로 꼭 필요한 데이터만 가져올 것!
- 인덱스 활용
- WHERE, ORDER BY, JOIN에서 자주 사용되는 컬럼은 인덱스로 지정해 데이터를 빨리 찾을 수 있도록
- 인덱스로 지정되어도 함수가 적용되면 인덱스로 사용할 수 없기 때문에, 인덱스로 지정된 컬럼에 함수 적용 등 추가 연산을 하지 않음
- 인덱스가 지원하는 연산자는 사용해도 괜찮음!
- B-Tree: <, <=, =, =>, >, IN, BETWEEN
- Hash: =
- 인덱스가 지원하는 연산자는 사용해도 괜찮음!
- 매번 새로운 쿼리를 만들어 실행하는 서브 쿼리보다 미리 최적화된 방법으로 데이터를 연결하는 JOIN을 활용하는 것이 더 좋음
- LIKE를 활용해 문자열을 검색할 때, 문자열의 시작 부분을 고정할 것.
- WHERE name LIKE 'apple%' 이라고 한다면 B-Tree 인덱스를 사용할 수 있지만,
WHERE name LIKE '%apple%' 이라고 한다면 결국 모든 데이터를 일일이 다 검색하게 됨
- WHERE name LIKE 'apple%' 이라고 한다면 B-Tree 인덱스를 사용할 수 있지만,
- INNER JOIN을 OUTER JOIN보다 우선적으로 고려할 것
- CASE를 UNION보다 우선적으로 고려할 것
728x90
'데이터분석 > SQL' 카테고리의 다른 글
| database overview (1) | 2024.07.06 |
|---|
'데이터분석/SQL' Related Articles
more
